Prompting Guide for Developers
As a senior Python developer working with GPT 4.1, I’ve shifted from “talking to an LLM” to engineering smart behaviors.
Prompting has become a powerful tool — not just for asking questions, but for crafting complex workflows, guiding reasoning, and orchestrating tools:

Here’s my distilled guide to getting the most from GPT, built from OpenAI’s recommendations and my own field practice.
🎯 Start With Intent
When writing prompts, clarity equals control. I always begin with a clear intent:
# Role
You are a senior Python code reviewer. Your job is to analyze a Pull Request for quality, maintainability, and adherence to Python best practices.
# Instructions
- Strictly follow **PEP 8** (style guide), **PEP 257** (docstrings), and common Pythonic conventions.
- For any Pydantic models:
- Check that models are used appropriately to validate and serialize data.
- Review use of `BaseModel`, `Field`, type annotations, and validators (`@validator`, `@root_validator`).
- Suggest use of newer Pydantic v2 features if applicable (e.g., `model_config` or `field_validators`)
- Identify and point out **missing or unclear comments**, poor variable naming, and any opportunity for cleaner abstractions.
- Highlight **ineffective error handling**, especially unhandled exceptions or overly broad `except` blocks.
- Use a respectful, helpful tone.
- End your turn **only after** providing a full, structured review including suggestions for improvements.
# Plan
1. Read and understand the code’s purpose and structure.
2. Examine all class and function definitions, especially Pydantic models.
3. Validate usage of Pydantic: fields, defaults, type hints, and validation logic.
4. Review for **style issues**: spacing, naming, formatting, etc.
5. Evaluate **code clarity**: logic structure, readability, and comments.
6. Analyze **docstrings** and function annotations for completeness and accuracy.
7. Examine **error handling**: try/except patterns, specific exception types, and logging.
8. Suggest improvements section-by-section.
9. Finish with a concise **summary of strengths and improvements**.
# Output Format
- 🔍 **Section-by-section review** (line references if possible)
- ✅ **Strengths**
- ⚠️ **Issues found**
- 🛠 **Suggestions for improvement**
- 🧠 **Final recommendation**These sections steer the model like a well-defined function signature.
🔄 Agentic Reminders

I embed three key reminders in system prompts:
You are an agent — keep going until the task is done. Do not yield back to me until you've verified the fix.
If you're unsure about any file or logic, use your tools to explore and confirm. **Never guess.**
Before calling any tool, **plan out your reasoning** step by step, then reflect after each call.These lines drastically improved the model’s autonomy and lowered hallucination risk in my agentic workflows.
🔧 Use the Tool Field, Not Prompt Hacks
Stop injecting tool descriptions into the prompt body. GPT is trained to use tools declared via the OpenAI tools field. I define tools clearly like so:
python_tool = {
"name": "python",
"description": "Run Python code or shell commands (e.g., !ls, !cat).",
"parameters": {
"type": "object",
"properties": {
"input": {"type": "string", "description": "Python or shell code to execute."}
},
"required": ["input"]
}
}Then I add sample usage examples in a separate #ExamplesSection if the tool is complex.
🧩 Prompting for Chain-of-Thought
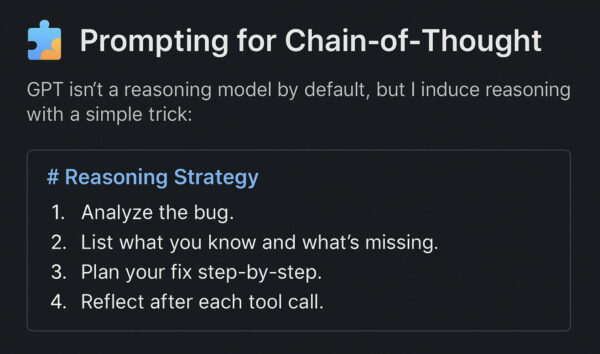
I’ve seen a 4–5% increase in agentic task success when this kind of planning is explicitly required.
📏 Long Context Best Practices
With GPT 1M-token window, long context is a dream — but performance depends on instruction placement:
- 📍 Put instructions both before and after your context block.
- ⚠️ Avoid overloading with low-quality context; prioritize relevance.
✨ Instruction Following Tips
GPT is very literal. Be exact:
- Avoid underspecified prompts.
- Add # Sample Phrases or Example blocks to reinforce tone and format.
- Use an “Instructions” section at the top and reference it in your Examples.
- Don’t mix conflicting guidance (the last instruction will often win).
Example:
# Instructions
- Never end without verifying tests.
- Always print the exact `TypeError` traceback if mentioned.📚 Final Advice
- Use markdown for clean formatting in long prompts.
- Watch out for hallucinated tool inputs — explicitly instruct fallback behavior.
- Avoid quoting too many sample phrases unless you want parroting.
- Prefer instructing what to do if unsure, rather than just saying “never do X.”
Prompting GPT is more like designing a UI for a brain — clear roles, tight feedback, and good defaults win every time.